著者:hugeh0ge
はじめに
この記事は、Fuzzing Farmシリーズ全4章のパート2で、パート1の記事「Fuzzing Farm #1: fuzzufを使ったGEGLのファジング」の続きです。
パート1の記事でも紹介したように、弊社のFuzzing Farmチームでは、弊社が開発しているファジングフレームワークfuzzufを活用し、ソフトウェアのバグを見つける活動もしています。Fuzzing Farmチーム以外でも、業務として我々がファザーを扱う機会は少なくありません。特に、fuzzuf自体の開発やその他の研究開発において、さまざまなファザーの性能を評価したい場面は多々あります。
しかし、ファザーの性能評価に関して整理された文書は少なく、また、性能評価には数多くの落とし穴が存在します。十分に注意して性能評価をしなければ、誤った結論を出しかねません。コードカバレッジが大きいほどファザーとしての性能が良いのでしょうか?クラッシュをより多く見つけられるファザーが優秀なのでしょうか?
ファザーを性能評価する上で、適切に実験を設定し、有益な結論を導き出すことは非常に難しいことです。残念な事実として、科学的に正しく実験すべきであるアカデミアにおいてすら、統計的に間違った方法で結論を急いでしまう場合や、推奨される実験設定についてファジング界隈としての合意を得られていない場合があります。
そこで、この記事では、社内で何度も実施したファザーの性能評価で得られた知見をもとに、ファジングの性能評価に関する注意点や推奨する実験設定を紹介します。
ファジングの問題点
一般的な推奨実験設定を紹介する前に、まずは、ファザーの性能評価において問題となるポイントを一通り詳しく説明します。
評価指標の曖昧さ
ファザーの”性能”を評価するにあたって、まず問題となるのは、評価指標の設定です。
ファザーの目標は一般には(バグ・脆弱性に起因する)クラッシュの発見であるため、「クラッシュをたくさん発見できるファザーほど性能が良い」と多くの人は考えるでしょう。
しかし、仮に、「ファザーAがクラッシュp, q, rを見つけ、ファザーBがクラッシュr, sを見つけた」という状況で、クラッシュを1つ多く見つけたファザーAのほうが優秀だと断言できるでしょうか。この場合、ファザーAがクラッシュsを見つけられていない、という事実を踏まえて判断しなくてはなりません*1。もし、この結果だけでファザーAの方が優秀だと主張するなら、「見つけられるクラッシュの種類などを考慮せず、幅広いPUTにおいて一般に多くの数のクラッシュを見つけられるようなファザーを評価したい」というモチベーションが前提になくてはなりません1。
また、クラッシュの個数を評価指標として用いる場合には、できるだけ精度の高いcrash deduplication(重複除去)が必要であることも注意点になります。ミューテーションベースのファザーは似たような入力を多く生成するので、同じ原因でクラッシュを引き起こす入力を大量に生成します。通常、ファザー自体は、クラッシュの原因を特定する機能を持ち合わせておらず、クラッシュを引き起こす入力の簡易的な分類しかしません。結果、多くの場合「クラッシュを引き起こす入力を発見した数 ≠ 見つけたバグ・脆弱性の個数」になります。ファザーAがクラッシュrを起こす入力を100個発見し、ファザーBがクラッシュrを起こす入力を1個発見した場合に、クラッシュを発見した数に99個の差があると考えてはなりません。(図1)

図1. ファザーAの方が発見したクラッシュ数は多いが、すべて同じバグを引き起こす入力
さらに、より根本的な問題として、実験の期間が挙げられます。実世界のソフトウェアに対して数日間ファザーを回しても、ほとんどの場合、発見できるバグ・脆弱性はたかだか数十個程度にとどまります。そのため、複数のファザーの間に有意な差が出ないことが多くあります。特に、どのファザーもクラッシュを発見できなかった場合は、何も評価できなくなってしまいます。
このように、発見したクラッシュの個数でファザーの性能を評価できない場合には、コードカバレッジ(到達できたコードブロックなどの量)の大きさを代替指標とすることが一般的です。これは、コードカバレッジの大きさと発見するクラッシュの個数に相関があるという事実が、広く信じられている*2からです。しかし、コードカバレッジとクラッシュの間に比例関係があることは認められていません。したがって、コードカバレッジの優劣だけを見て、発見できるクラッシュ個数の潜在的な期待値に優劣をつけてはいけません。無論、「コードカバレッジが大きいほどクラッシュを見つける可能性が高そうだ」という直感に大きく反するケースというのは稀です。たとえば、2つのファザーのコードカバレッジに数倍の差がついているような明らかな状況では、コードカバレッジが大きい方が優秀である、と判断して良いでしょう。しかし、「ファザーA, B双方ともにクラッシュを一つも見つけておらず、ファザーAのカバレッジがファザーBの平均1.01倍」といった状況では、「ファザーAのほうが一般にクラッシュを見つけやすい」と考えるのは危ういということを念頭に置くべきです。
クラッシュ個数やコードカバレッジといった、“y軸”に相当する値に注意が必要なことはここまで述べてきたとおりですが、”x軸”に相当する値にも注意が必要です。ファザーの性能比較では、x軸を経過した時間、y軸をコードカバレッジなどに設定してグラフにプロットすることが多いです。しかし、注目したい要素によっては、x軸をPUTの実行回数にして、PUTの実行回数に応じたコードカバレッジの大小を比較したほうが良い場合があります。(図2)

図2. PUTの実行回数をx軸にしたグラフの例(EcoFuzzより引用)
たとえば、ファザーに何らかの最適化を施し、その効果を測定したかったとします。適用した最適化が、純粋に実行速度の向上のみをもたらすものならば、時間をx軸としたグラフで評価したいはずです。なぜなら、実行速度が向上しても、「1回のPUT実行で新しいコードブロックを引き当てる確率」が変化するわけではなく、実行回数をx軸としたグラフに差が出るはずがありません。言い換えると、実装した最適化にバグがないかを確認する上では、実行回数をx軸としたグラフに変化が生じていないかを確認するという手段が考えられます。
一方で、施した最適化が新しいミューテーションの追加などで、「1回のPUT実行で新しいコードブロックを引き当てる確率」が変化していることを期待している場合には、時間がx軸であるグラフで評価するよりも実行回数がx軸であるグラフで評価したほうが精度の高い評価ができるでしょう*3。
コードカバレッジに関するもう1つの注意として、「コードカバレッジの大きさ ≠ 新しいコードブロックを発見した回数」であることも意識しましょう。ほとんどの場合では、新しいコードブロックを通過した際には、そのコードブロックから先にも処理は後続しているので、同時に他の新しいコードブロックを見つける可能性が高いです。ファザーが1万個のコードブロックを見つけていたとしても、カバレッジの上昇を引き当てた回数は1000回程度ということは少なくありません。たとえば、「カバレッジ上昇を引き当てる回数は非常に多いが、達成する正味のコードカバレッジは小さいファザー」と「カバレッジ上昇を引き当てる回数は少ないが、達成する正味のコードカバレッジは大きいファザー」の2者を比較して、そういった特殊な性質に気づかないまま評価してしまう可能性もあります。
極端な例として、図3ではファザーAもBもコードカバレッジとしては同じ値を示していますが、カバレッジの上昇回数(新しい分岐を発見した回数)や到達したパスは異なります。もしファザーAのミューテーションの性能が悪くて一番左のパスにしか到達できないと考えれば、ファザーBの方が優秀と考えられます。一方で、もし一番左のパスに到達する条件が非常に複雑で、それ以外がエラー処理のような興味のないパスだとすれば、重要なパスを見つけたファザーAの方が優秀と考えられます。また、この図では同じコードカバレッジになっていますが、CFG(Control Flow Graph)によっては、ファザーAのコードカバレッジがファザーBより大きくなったり、逆に小さくなったりすることもありえます。このように、コードカバレッジを単純に比較できるかは、ファザーの性質によって異なります。

図3. ファザーAもファザーBも同じカバレッジだが、発見したパスは大きく異なる
ファザー自体の不確定性
ファザーはさまざまな入力を試すため、乱数にもとづいてテストケースを生成したり、ミューテーションしたりします。乱数に依存する以上、その動作には不確定性があります*4。また、ファザーが性能を発揮できるかは、動作時間やPUTの種類によっても異なるでしょう。そのような不確定性によって発生する問題について議論します。
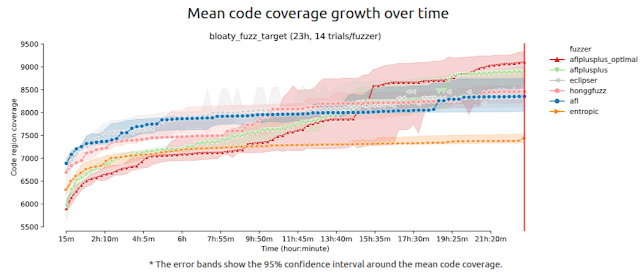
図4は、fuzzbenchによる実験の結果です。横軸は経過した時間、縦軸はその時点でのカバレッジの大きさ(Code Region)を表しています。各ファザーを動かしているインスタンス数は14個で、ドットの入った太い線はカバレッジの平均値、上下のエリアは95%信頼区間を示しています。

図4. 各種ファザーのカバレッジを23時間計測した結果
グラフを見ると、23時間経過した実験終了時点では、平均値を見ても信頼区間を見ても、「高い確率で、aflplusplus_optimalが一番大きいコードカバレッジを達成する」という結論が得られるかと思います。しかし、仮にこの実験を12時間で停止させていた場合には、aflplusplus_optimalの平均値はAFLにすら及んでいません。
このように、カバレッジの上昇は時系列データであり、ファザーごとにその上昇の傾向は異なるため、ある時間において最も強いとされているファザーが、更に時間が経過した際にも最も強いかどうかは分かりません。
時系列を持つことによって、他にも問題が生じます。冒頭でも述べたように、そもそもファザーはランダムに振る舞うので、完全に同じPUTを同じ設定でファジングしたとしても、乱数の情報源が異なると、結果も全く異なります。分かりやすい例として、この問題について論じている以下のツイートのグラフを引用します。
Let's talk a bit about fuzzer benchmarking. I'll start off with some data directly from fuzzbench, of `aflfast` fuzzing `libjpeg-turbo`. Here's what the 20 runs of `aflfast` look like. https://t.co/Hsromay7os pic.twitter.com/gy2Eo2NFx3
— Brandon Falk (@gamozolabs) August 9, 2020

図5. 1インスタンスで20回fuzzerを回した際の各カバレッジ計測結果
このグラフも横軸を時間、縦軸をカバレッジとしたグラフで、同じファザー(aflfast)を20回同じマシンで動作した際のカバレッジ変化を示しています。
グラフを見ると、少ないインスタンス数での性能評価は危険であることが理解できるでしょう。たとえば、各ファザーをたった1つのインスタンスだけで評価するということは、大まかに言えば、このグラフの20本の曲線からたった1本をランダムに選び、それだけを見て評価することと同じです。その1本から期待されるファザーの平均的な振る舞いと、これら20本すべてから期待される平均的な振る舞いは大きく異なるでしょう。
また、平均値と信頼区間のみを表示したfuzzbenchのグラフ(図4)と、実際の20個のインスタンスのカバレッジを表示したグラフ(図5)を見比べてみましょう。計測時間やPUTに違いはあるものの、平均値や信頼区間はなめらかに変化しやすい傾向があります。一方で、個々のインスタンスのカバレッジは階段状の変化が多く見られます。
というのも、ファザーが新しいコードブロックを見つけられず、行き詰まる期間は多くあります。その結果、一定期間コードカバレッジが変化しない時間ができ、グラフ上にplateau(平坦な領域)が生じます。すべてのインスタンスがほぼ同時にplateauを抜けるということが起きない限りは、平均値などのデータは階段状にはなりづらいです。
そのため、平均値および分散のみを表示したグラフでは、実際の各インスタンスのカバレッジは階段状の極端なものである可能性に留意したほうがよい場合があります。
コンフィグへの強い依存
ファザーの性能は、実験設定が一つ異なるだけで大きく変わる(変わって見える)可能性があることを常に注意しなければいけません。
最も分かりやすく変化を生じさせる設定は、使用するPUTの違いです。fuzzbenchの実験におけるいくつかのPUTの結果を図6.1から6.3に示します。

図6.1. freetype2-2017をPUTにした際のカバレッジ変化

図6.2. bloaty_fuzz_targetをPUTにした際のカバレッジ変化

図6.3. lcms-2017-03-21をPUTにした際のカバレッジ変化
これらの図を見ると、23時間でもっとも高いカバレッジを得られたファザーは、PUTによって異なることが分かります。
また、当然ながら同じPUTでも、そのソフトウェアのバージョンやビルド方法の違いによっては、ファザーの振る舞いが全く変わるかもしれません。特に、計装*5の方法が異なるだけでも性能に差が生じることがあります。
次点で最も変化が生じやすい設定は、初期シードと辞書です。極端な例として、PDFファイルをパースするPUTに対して、まともな初期シードが1つもない状況と、初期シードとしてPDFファイルを1つ与えられている状況を比較してみましょう。
PDFファイルの初期シードがない状況では、まずPDFファイルのヘッダ(およびトレイラ)を突き止めないことには、ヘッダの処理より先のコードブロックに到達することができません。更に、pdfファイルを構成するオブジェクトやxrefといったデータの書式をミューテーションで特定しないことには、それらに関する処理をテストすることもできません。比較的単純なランダムミューテーションを加えるだけのファザーが、それらの書式を偶然発見する確率は非常に低いことは容易に想像できます。
一方、まともなpdfファイルが1つ初めから与えられている場合には、ヘッダのバリデーデーションでエラーになることもなければ、オブジェクトやxrefの構造をファジングで見つける必要もありません。また、PDFファイルのように複雑なファイルフォーマットでは、JavaScriptやColor Profileなど、他のフォーマットが埋め込まれていることがあります。「フォーマットを知らなければ知らない3ほど、処理を継続させて新しいコードブロックを見つけるのが難しい」と考えるならば、埋め込まれている別のフォーマットも含め、初期シードとして多様なファイルが与えられるほど有利になるでしょう。
辞書についても同様です。"%PDF-1.6", "%%EOF", "/Parent", "xref"のようなキーワードが辞書にある場合、それらを挿入するだけで関連する処理が実行される可能性が高くなります。もし、これらが辞書に存在しなければ、ランダムな文字列生成でキーワードが偶然生み出されることを願うしかありません。
このように、ファザーが同じであっても、あらかじめ与えられている事前知識の差が性能の差を生み、全く別の結果を見せることは多々あります。
事前知識の与え方には初期シードや辞書の他にも、様々な形態があります。より暗黙的な事前知識の与え方としては、ハイパーパラメータの調整が挙げられます。典型的には、ファザーは多くのパラメータを持っており、それらをマクロなどでコンパイル時に指定する形を取っています。たとえば、AFLファミリーはMAX_FILEと呼ばれるハイパーパラメータを持っており、MAX_FILEバイトまでのファイルしか生成できません。デフォルトでは、この値は1MBに設定されており、比較的様々な大きさのファイルを生成する可能性を持ちます。しかし、たとえば「PUTは100バイトまでの入力しか受け付けず、それより大きな入力はすべて弾く」ということがわかっている場合、このパラメータを100まで下げたほうが、意味のない入力を生成する可能性が減少し、より効率よくファジングできるでしょう。こうしたパラメータ1つの変化で、性能が大きく増減する可能性があります。
さて、ここまでで「同じファザーでも事前知識の有無によって大きく性能が異なりえる」ということを説明しました。では、異なるファザーの比較において、事前知識の有無はどのような影響を与えるのでしょうか。
初期シードや辞書をファザーごとに変更させるのは、性能評価としては明らかにアンフェアです。もし条件をなるべく統一すれば、実験設定としては有効でしょうか。初期シードが無かろうが、10000個の初期シードを使おうが、すべてのファザーで同じ条件を適用していれば、実験としては成立しているはずです。
しかし、恐ろしいことに、実験設定ごとにファザーの優劣が逆転することもあります。たとえば、まともな初期シードがまったく無い設定と、まともな初期シードが十分にある設定の比較を考えると分かりやすいでしょう。
前者の設定においては、これまで説明してきたとおり、比較的単純なランダムミューテーションを備えたファザーは行き詰まる可能性が高いです。そのような状況で、新しいコードブロックを引き当てplateauを抜け出しやすそうなのは、REDQUEENのように特殊な工夫を用いているものや、SMTソルバーを導入したconcolicなファザーなどです。
一方、後者の設定では、ランダムミューテーションのみを用いても「特定のキーワードを引き当てないとplateauから抜け出せないケース」に対処できる可能性は十分に高いです。初期シードがそもそもキーワードを引き当てているケースであるというのはもちろんのこと、さらには、cloneやsplicingといった他のシードからバイト列をコピーするミューテーションのおかげで、新しく生成される入力もキーワードを持つ可能性が十分に残されています。
つまり、初期シードがあるだけで、辞書のような効果を一定持つということです。結果として、前者の設定では特殊なファザーが、後者の設定では単純なランダムミューテーションを持つファザーが上位に来る可能性があります。
では、どのような実験設定が良いのでしょうか。
シード選択もPUT選択の話と同様に、的確な正解はありません。強いて言うならば、実際にファザーを利用する際に使う設定に近づけるのが良いでしょう。
たとえば入力のフォーマットがPDFファイルなど一般的なものの場合、すでに初期シードや辞書がパブリックに存在しており、長年チューニングされてきています。このようなシードは誰でも使うことが想定されるので、性能評価に利用しても問題ないでしょう。
一方で、そういった事前知識を使えない状況下でファジングすることを想定しているファザーならば、事前知識を与えない状況でベンチマークを取ることも合理的であると言えます。もちろん、今評価しているファザーが何を目的としており、実験設定がどのような仮定のもとに組み立てられたのかを、明確に示すことが重要です。
ここまで実験設定について説明してきましたが、変化をもたらし得るのは明示的なパラメータに限らないことにも注意しましょう。以下はAFLのコードの一部です。
/* Let's keep things moving with slow binaries. */
if (avg_us > 50000) havoc_div = 10; /* 0-19 execs/sec */
else if (avg_us > 20000) havoc_div = 5; /* 20-49 execs/sec */
else if (avg_us > 10000) havoc_div = 2; /* 50-100 execs/sec */
.....
stage_max = (doing_det ? HAVOC_CYCLES_INIT : HAVOC_CYCLES) *
perf_score / havoc_div / 100;
.....
/* We essentially just do several thousand runs (depending on perf_score)
where we take the input file and make random stacked tweaks. */
for (stage_cur = 0; stage_cur < stage_max; stage_cur++) {
このコードは、1秒間に何回PUTを実行できているかで、1つのシードを何回ミューテーションするかを決定しています。
つまり、同じPUTを同じファザー、同じ実験設定でファジングしても、実験に使うマシンやCPU負荷の差などによって異なる振る舞いを示し、異なる結果が生じ得ます。本来、純粋にファジングアルゴリズムを評価する上では、どのようなマシンでも一貫性のある振る舞いをするべきですが、このように実用性を目的とした最適化が原因で、一貫性がなくなることがあります。したがって、実験設定のみならず、実験環境についても可能な限り同一に保つ努力をすべきでしょう。
推奨される実験設定
ここまでに挙げた問題点を踏まえた上で、推奨できる実験設定を紹介します。
仮説を定める
科学的な実験全般において言われることですが、何も仮説がない状態での実験はなるべく避け、明確に示したいことや確認したいことを定めてから実験しましょう。多くの場合、仮説のない状態で実験すると、無意味な実験になったり、結果の観察にバイアスがかかって疑似相関などに注目してしまいやすくなったりしてしまいます。
評価指標を決める
まず初めに、評価指標としてクラッシュ個数を使用するのか、コードカバレッジを使用するのか、あるいは他の指標を使うのかを決めなければなりません。
クラッシュ個数で評価する場合、評価のデータセットにはMAGMAを使うことを推奨します。現状、発見されたクラッシュのdeduplicationを完全に行えるデータセットとしては、MAGMAが広く認知されているためです。クラッシュ個数を評価に使う上で、何らかの理由でMAGMAのデータセットが使えない場合は、クラッシュのdeduplicationをできるだけ高い精度で行う仕組みを用意する必要があります。たとえば、AFLファミリーに実装されているdeduplicationアルゴリズムは非常に精度が悪く、ほとんど意味がありません。
PUTとコンフィグを決める
デバッグ目的などの特殊なモチベーションが無い限り、性能評価では必ず複数のPUTを用意する必要があります。著者の経験上、同じ入力フォーマットを持つPUTで実験をする(「このファザーがpdfに強いことを示したい」などの仮説を持っている)場合は少なくとも3個、任意の入力フォーマットで実験する場合は6個以上のPUTを使うことが望ましいです。それより少ないPUTの個数での実験結果を見ると、偶然なんらかの傾向があるように見えることがあり、性能評価の主張としては弱いです。On the Reliability of Coverage-Based Fuzzer Benchmarking(参考文献[1])では、少なくとも10個のプログラムを用意するべきであると書かれています。
使用するPUTは、自分で書いたプログラムや数十行・数百行の小規模なプログラムよりは、著名なOSSなどの、ある程度大きなソフトウェアで、かつ実世界で利用されているものが望ましい*6です。これは、「(普通、ファザーは最終的には実用することを目的としているから)できるだけ実用的な結果を得たほうが良い」という考え方によるものです。
また、PUTは可能な限りランダムに選択することも重要です。これは、実験者による恣意性をできるだけ排除し、選択バイアスを減らすための措置です。もちろん、「著名なOSSであるほうが良い」といった条件をPUTに同時に課したいはずです。そのため、あらかじめ条件を満たすPUTをリストアップして母集団を作り、そこから複数個ランダムに選択する形を取るとよいでしょう。
PUTを決定したら、PUTごとのコンフィグ(初期シードや辞書、その他ファザー起動時に設定できるパラメータ)を決めます。これについても原理的には、「できるだけ実用的な結果を得たほうが良い」というモチベーションに基づいて決めることを推奨します。AFLが用意している辞書のプリセットが使えるなら使ってもよいですし、初期シードとして良さそうな既存のコーパス(e.g. https://github.com/mozilla/pdf.js/tree/master/test/pdfs)があるならばそれを使ってもよいです。
実験環境・実験時間・実験インスタンス数を決める
実験を始める前に、実験環境、実験時間、そして実験に使うマシンのインスタンス数を決める必要があります。これらのパラメータは、前節「PUTとコンフィグを決める」で決定したPUTの個数および、実験者の持つ時間猶予・資金・計算資源と相談して決めなければなりません。理想的な値は断言しにくいので、まずは理想的な条件について説明した後、どこを譲歩できるかという点について議論していきます。
実験を回すマシンは、できるだけ同一の環境になるようにしましょう。たとえば、一つのマシン上ですべての実験を取る、SaaSで同一リソースのインスタンスを用いる、などが挙げられます。
実験時間については、前述した通り「ある時間において最も強いとされているファザーが、更に時間が経過した際にも最も強いかどうかは分からない」という問題があります。極論、どれだけの時間ファザーを実行してもこの懸念が解消されることはありません。しかし、直感的に考えると、あるいは経験に照らし合わせても、ファザーを長期間回せば回すほど、そのような逆転現象が起きる可能性は減っていきます。参考文献[1]においても、経験的な実験の上で、少なくとも12時間、基本は24時間以上実験を回すことを推奨しています。
実験インスタンス数は、次節「統計的に評価する」で説明する統計的な検定に影響してきます。直感的に、実験インスタンスが多ければ多いほど、ファザーの平均的な振る舞いが良い精度で予測できると考えられるでしょう。参考文献[1]においては、少なくとも10個、基本は20個以上のインスタンスを使うことを推奨しています。
では、次に実験にかかる時間を計算してみましょう。単純に考えると、実験に必要となるCPU時間は次のように計算できます。
(必要時間[h])=(PUTの個数) x (インスタンス数) x (実験時間 [h])x (比較するファザーの個数)
もし、すべてについて[1]で推奨されている数値を採用した場合には、1つのファザーに対してすら、10 x 20 x 1 [d] = 20 [CPU・d]という極めて膨大なリソースと時間が必要になります。したがって、多くの場合は、やむを得ず何かを譲歩しなくてはなりません。
まず、実験時間については、経験上24時間より短くするべきではありません。むしろ、余裕があるときは24時間よりも更に伸ばすべきであると考えます。無論、CPUの性能やインスタンスの並列数によって同じ時間で実行されるPUTの回数は全く異なるため、時間について制限を設けるのはナンセンスではないかという考え方はあります。しかし、コンシューマ向けの一般的なCPUよりも強力なCPUで構成されているDGXを用いて実験した経験上は、24時間経っても大半のインスタンスはカバレッジが上昇しつづける傾向にあります。そのカバレッジ上昇によって新しい傾向が見えてくることもあったため、著者の経験上、いかなる環境においても24時間は最低限回したほうが良いという確信があります。
また、実験インスタンスを1つのマシン上で複数個回すことによって、多少の時間を削減できる可能性があります。ただし、以下の点には注意しましょう。
- 実験マシンの負荷が大きくなりすぎないようにする。
- PUTが1秒間に何回実行されるかを観測し、下がりすぎない程度に収める。
- 「どの程度の実行回数なら下がりすぎてないのか」には数値的な基準はありませんが、たとえばfuzzbenchなどで標準とされているベンチマークで使われているCPUに近い性能のCPUを使うなどが考えられます。
- 通常、物理コアと同じ数までであれば並列に動かしても問題ない可能性が高い*7です。しかし、1つの物理コアで1つのインスタンスを実行しても、性能が下がってしまうことがあります。特に、数百コアあるマシンで数百個のインスタンスを立てると、実験が無意味になることもあるほど、forkなどの処理が非常に遅くなります。プロセス数が増えるほどOSの処理が重くなるのは必然で、OSの限界であるともいえるでしょう。したがって、余裕を持ってインスタンス数を決めるべきです。
- 異なる(=比較する)ファザーを同時に回さないようにする。
- ファザーAの負荷がファザーBに悪影響をもたらすということがないようにするためです。
- 悪影響が出ることが考えづらく、論文などに掲載しないデータ(=社内で使うデータなど)を計測する場合は、最悪の場合は同時に回しても良いでしょう。ただし、そのことは必ず明記するべきです。
どうしても計算資源が足りない場合は、PUTごとに使用するマシンが統一されていれば、複数の異なるマシンを使用しても構いません。
また、論文投稿などを視野に入れておらず、やむを得ない場合は、PUTの個数を10個未満に減らすことも視野に入れて良いでしょう。ただし、前述の通り、可能な限り最低でも6個のPUTがあったほうが良いです。それよりも更に個数を減らす場合には、確証バイアスに十分気をつけなければなりません。
統計的に評価する
これが最も難しいパートです。残念なことに、統計的評価を正しく実施できていない論文も多く見られます。ファジングキャンペーンはランダムな時系列データとみなせるので、その良し悪しを判断するには、統計的な手法によって比較するのが妥当です。結局のところ、ファジングの文脈に限らず、統計的検定を正しく行うのは難しいという話になります。この点について詳しく説明するには十分な数学の素養を必要とする上、本文書の趣旨から外れてくるため、どういうミスを犯しやすいかについてのみ説明します。
- ノンパラメトリックな検定を使わなければならない。
- 直感的に考えると、ファジングキャンペーンのランダム性には「正規分布にしたがっている」といった性質の良さが認められるはずもありません。分布に対しては、なるべく仮定を置かないべきです。すなわち、ノンパラメトリックな手法を用いるのが適切でしょう。
- これについては、大抵の論文が守れています。
- p値の閾値となる有意水準αが緩すぎる・恣意的に見える。あるいは、サンプル数が不十分である。
- αとは、簡単に言えば「検定の結果、ある仮定が真であると判断された場合に、実は仮説が成立していなかった確率(または1-αに反転してその逆)」を表す値で、極端なことを言えばα = 0.50とすると、検定の結果が真であっても、仮説が成立している確率が50%ということになり、何の意味もなしません。
- αの設定は自由であるため、分野によって様々なデファクトスタンダードがあります。ファジング界隈ではp<0.05が多いです。著者としては、p<0.01以上を使うべきであると考えていますが、それ自体は個人的な信条であるため問題ではありません。しかし、たとえば統計的検定の結果を見てからαを決めることは許されません。また、近年では、そもそもαをあまり気にせず、p値自体を表示する傾向にあるという印象を受けます。
- ノンパラメトリックな検定は、パラメトリックな検定よりも仮定が少なく、通常、多くの情報(=サンプル数)を必要とします。一方で、ファジングキャンペーンは1回の試行が非常に重く、なかなかインスタンス数を増やすことができず、有意な結果を得るのは困難です。(だからこそ、p値を後から変えるといった不正が発生してしまいます。)たとえば、インスタンス数10と20では、検定上大きな違いをもたらすことがあります。
- 多重検定の問題に対処していない。
- 残念なことに、この点について正しく対処できている論文はあまり見かけません*8。サンプル数も含め、実際適切に扱うのが困難であり、結果として曖昧になっている印象です。
ファジング界隈の論文中でよく使われている検定は、マン・ホイットニーのU検定です。しかし、この検定は元来「2つの集団が従う分布が異なるかどうか」または「ある集団のrank sumがもう一つの集団のrank sumよりも優位に優れているか」を判断する能力しかなく、「ある集団の平均・中央値がもう一つの集団の平均よりも有意に高いか」は一般には判断できません。
また、そもそもファジング界隈の設定では、マン・ホイットニーのU検定よりもブルンナー=ムンツェル検定の方が使用に適しており検出力も高くなるはずです。しかし、それについて議論がなされている様子がない上、マン・ホイットニーのU検定を推奨する論文が引用されることが原因となり、実質的にデファクトスタンダードになってしまっている印象を受けます。
このように、PUTごとのファザーの比較(= 統計的手法を適用できる範疇)ですら、気にすべき点が数多く存在します。さらに困るのが、PUTをまたいで結論を出すタイミングです。
先に説明したとおり、同じファザーを使ってもPUTごとに全く異なる傾向や結果を見せるため、「ファザーAとはこういうものである」という結論はほとんど得られません。さらに、PUTがファザーの性能に与える影響というのは、全く持って数式などのモデル化できません。また、実験で用いられるPUTはたかだか数十個で、互いに他とは異なる性質を示すので、統計的手法を援用できる設定とは言えません。
これに関しては、実験者が自身で納得できる方法により結論を導き出すしかないでしょう。たとえば、「8個のファザーを比較する。10個のPUTで各ファザーが達成したコードカバレッジを大きい順に並べた時、3位までにランクインした回数を計算する。その値が最も大きいものを最も偉いファザーとしてみなす。」といった、アドホックな方法を各自で考えるほかありません。
このように、ファジング界隈では実験結果の統計的評価手法に完全なコンセンサスが得られていない状況です。実験結果から何を判断したいのかに応じて、どのような統計的手法を使うか吟味する必要があるでしょう。
おわりに
この記事では、ファザーの性能評価をする際に陥りやすい落とし穴や、実験設定の組み立て方の注意点などを紹介しました。ファザーの性能評価をする際は、各ファザーの特性を理解した上で、調査したい課題に応じて適切な実験を設定しましょう。
今後も我々はさまざまなファザーの性能を調査し、fuzzufに取り入れるために開発・研究を進めていきます。
次回は、1-day exploitの開発で重要なパッチ解析の考え方について、Google Chromeの1-dayを例に紹介する予定です。お楽しみに!
参考文献
[1] Marcel Böhme, Laszlo Szekeres, Jonathan Metzman. On the Reliability of Coverage-Based Fuzzer Benchmarking. 44th International Conference on Software Engineering (ICSE 2022) https://mboehme.github.io/paper/ICSE22.pdf
[2] Marcel Böhme, Danushka Liyanage, Valentin Wüstholz. Estimating residual risk in greybox fuzzing. Proceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE 2021) https://mboehme.github.io/paper/FSE21.pdf
*1: 当然、ファザーBがクラッシュp,qを見つけられなかったという事実も考慮する必要があります。
*2: 「Code coverage for suite evaluation by developers」などを参照。
*3: もちろん、両方のグラフがあれば、追加した最適化が実行速度に影響していないことも同時に説明できます。
*4: たとえ乱数シードを固定できるにしても、乱数シードの値によって動作は必ず変化します。
*5: カバレッジ測定など、PUTからファザーに情報をフィードバックするためのコードをプログラムに追加すること。インストラメント。
*6: コンセプトの試験的な実装のため小さいプログラムでのみ動作するなど、特別な理由がある場合はその限りではありません。
*7: CPUコアにバインドするファザーの実装が多いため。
*8: Comparing Fuzzers on a Level Playing Field with FuzzBenchは適切に検定を扱っている良い例です。
No comments:
Post a Comment